
TechBlog
[MSSQL/SQL Server] 물리적 JOIN 방식 본문
MS-SQL에서 지원하는 조인 방식에는 크게 3가지가 있다.
- 중첩 반복(Nested Loops)
- 정렬 병합(Sort Merge)
- 해시 매치(Hash Match)
1. Nested Loops Join
1) 의미
선행 테이블의 결과 집합을 한 건씩 후행 테이블에 조인하고 이를 반복하여 최종 결과 집합을 만들어내는 조인 방식.
2) 특징
- 선행적
- 선행 테이블의 처리 범위가 전체 일의 양을 결정, 즉 선행 테이블의 결과 집합 건 수만큼 조인이 반복된다.
- 랜덤 액세스
- 조인 키(A.KEY=B.KEY)로 선행 테이블에서 후행 테이블에 액세스할 때 랜덤 I/O가 발생한다.
- 연결고리의 중요성
- 선행 테이블의 처리 row를 가지고 후행 테이블의 인덱스 페이지를 액세스하기 때문에, 후행 테이블의 인덱스 유무가 중요하다.
- 다른 방식에 비해 메모리 사용량 가장 적음
- 선행 테이블에서 후행 테이블에 액세스할 때 랜덤 I/O가 발생하므로, 선행 테이블의 카디널리티를 획기적으로 줄일 수 있다면 나머지는 수학적인 반복 연결이기에 메모리를 가장 적게 사용하는 조인 방식이 된다.
3) JOIN 과정
다음과 같은 쿼리가 있다.
select col1, col2
from Tab1 as A
inner join Tab2 as B
on A.KEY = B.KEY
where A.KEY = '111'
and A.col1 like '222%'
and B.col2 = '333'
이때 A.KEY, B.KEY에만 인덱스가 잡혀 있고, 통계에 의해 tab1이 선행 테이블로 선택되었다고 가정하자.
JOIN 과정을 간략하게 설명하면 다음과 같다.
① Tab1 테이블의 인덱스 페이지에서 A.KEY = '111'을 만족하는 데이터를 찾는다.
② 인덱스 페이지에서 찾은 결과로, 만약 A.KEY가 논클러스터드 인덱스라면 RID Lookup을 통해 Tab1 테이블의 데이터 페이지에 접근하고, 클러스터드 인덱스라면 리프 페이지가 데이터 페이지이므로 별도의 데이터 페이지에 대한 접근이 필요 없다. 여기서 A.col1 like '222%' 조건을 통해 한 번 더 필터링 된다.
③ Tab1 테이블의 결과 집합을 가지고, Tab1 테이블에서 Tab2 테이블에 랜덤 액세스하여 A.KEY = B.KEY라는 조인 조건을 만족하는 인덱스(B.KEY에 걸려 있는 인덱스)와 조인한다.
④ 조인된 결과에서, ( B.KEY가 논클러스터드 인덱스라면) RID Lookup을 통해 Tab 2 테이블의 데이터 페이지에 접근한다.
⑤ 조인된 결과 집합에서 Tab 2 테이블의 조건인 B.col2 = '333'을 만족하는 데이터만 운반 단위에 전달한다.
⑥ 앞서 where 조건에 의해 필터링된 Tab1 테이블의 행 수만큼 이러한 조인 과정을 반복한다.
2. Sort Merge Join
1) 의미
양쪽 테이블을 조인 컬럼 기준으로 정렬한 다음 병합하는 과정으로 조인하는 방식.
2) 특징
- 동시적
- 양쪽 테이블을 동시에 한 번만 스캔하고, 양쪽 테이블 모두 조인할 준비가 되었을 때 조인 시작.
- 양쪽 테이블을 한 번만 스캔
- Loop Join은 후행 테이블을 반복 스캔하며 조인하는 반면, Merge Join은 양쪽 테이블을 한 번만 스캔하고 조인.
- 정렬 작업에 따른 메모리 사용 증가 부담
- 정렬 작업은 메모리를 사용하기 때문에, 대용량 테이블일수록 부담이 커진다.
- 그러나 가공 없이 클러스터형 인덱스를 그대로 사용하게 되면 정렬하지 않아도 되므로 부담 X
- 최소 한 개 이상의 ‘=’ 조건이 있어야 함
- 단, full outer join의 경우 ‘=’ 조건 없이 merge join 가능
- 처리량이 많을 때 유리함
- 처리량이 많아지면 랜덤 액세스에 대한 부담이 증가하는 Loop Join과 달리, 스캔 방식으로 조인되는 Merge Join을 사용하면 성능상 이점이 존재함 (Merge Join에서 두 테이블의 크기는 성능과 관련이 없음)
3) JOIN 과정
다음과 같은 쿼리가 있다.
select col1, col2
from Tab1 as A
inner join Tab2 as B
on A.KEY = B.KEY
where A.KEY = '111'
and A.col1 like '222%'
and B.col2 = '333'
이때 A.KEY, B.KEY에만 인덱스가 잡혀 있다고 가정하자.
JOIN 과정을 간략하게 설명하면 다음과 같다.
① Tab1 테이블의 인덱스 페이지에서 A.KEY = '111'을 만족하는 데이터를 찾은 후 A.col1 like '222%' 조건으로 최종 필터링된 결과 행들을 A.KEY 값으로 정렬한다.
② Tab 2 테이블을 스캔하여 B.col2 = '333'을 만족하는 행들을 B.KEY 값으로 정렬한다. 이때 1, 2번 과정은 동시에 일어난다.
③ 정렬된 두 집합을 가지고, 양쪽 값을 동시에 스캔하면서 A.KEY = B.KEY를 만족하는 값에 대해 조인을 진행한다.
3. Hash Match Join
1) 의미
해시 키와 해시 테이블을 통해 조인을 하는 방식.
이때 해시 키는 해시 테이블의 인덱스 역할을 하며, 매칭되는 해시 키를 찾아서 조인을 진행한다.
테이블은 Build Input, Prove Input으로 나눠지며, 옵티마이저는 두 테이블 중 작은 테이블을 빌드 입력으로 설정한다.
| 입력 | 의미 |
| Build Input (빌드 입력) |
-해쉬 테이블을 만드는 데 사용되는 입력 |
| Prove Input (검색 입력) |
-해쉬 테이블을 탐색하는 입력 |
2) 특징
- 인덱스를 사용할 수 없는 환경에서 결과를 정렬할 필요가 없을 때 효율적으로 사용 가능
- 조인 조건 컬럼의 정렬이 필요하지 않으며, 해시 버킷의 순서대로 결과가 출력되므로 결과값은 정렬되어 있지 않음
- 해시 테이블 생성으로 메모리 사용량 증가 부담 존재
3) JOIN 과정
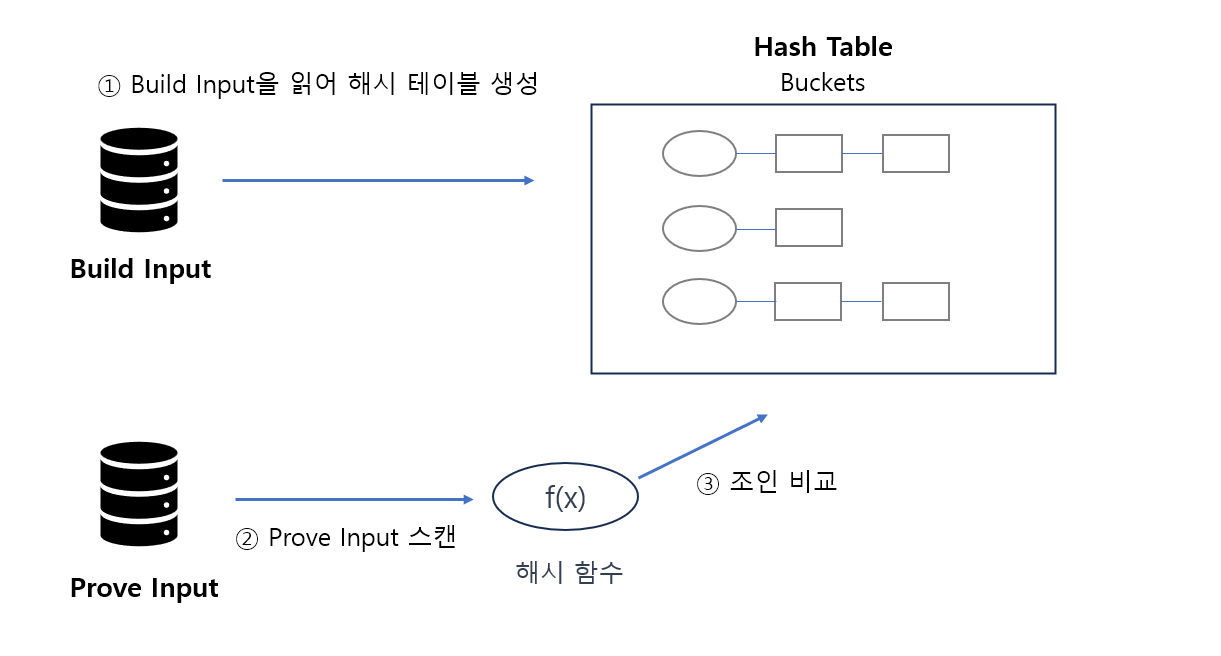
작은 테이블을 Build Input으로 설정하고, 이를 읽어 조인 컬럼에 해시 함수를 적용해 해시 키를 생성한 후, 해시 테이블을 생성하여 각 행을 해시 버킷에 삽입한다.
해시 테이블 생성이 완료되면 Prove Input을 읽어 해시 함수를 적용해 해시 키를 생성하고, 해시 테이블을 탐색하여 매칭되는 해시 키를 찾아 조인을 진행한다.
'DB' 카테고리의 다른 글
| [MSSQL/SQL Server] 복제(Replication) (0) | 2025.02.01 |
|---|---|
| [MSSQL/SQL Server] 파라미터 스니핑(Parameter Sniffing) (0) | 2024.12.01 |
| [MSSQL/SQL Server] JOIN 종류 (0) | 2024.05.25 |
| [MSSQL/SQL Server] 동적 쿼리 (0) | 2024.03.24 |
| [MSSQL/SQL Server] 트랜잭션 격리 수준 (0) | 2024.03.03 |

